

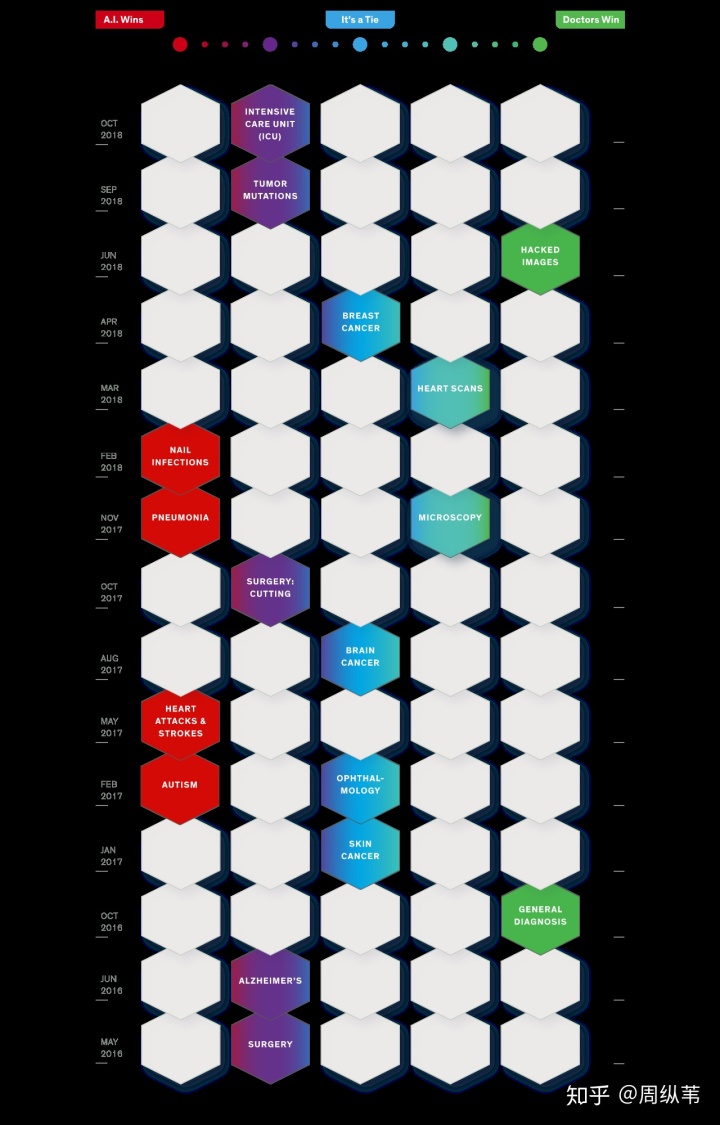
从人工到智能化
人工智能化十分火。医科院设立了课程内容让学员应用人工智能辅助专用工具。 “神经元网络鼻祖”Hinton推测说急诊科的医师将在5-十年內被电子计算机替代(Geoff Hinton: On Radiology),如同之前的高速路高速收费站,地铁火车高速收费站的工作中一样,自然不持这一见解也扪心自问(Despite AI, the Radiologist is here to stay)。整体而言人工智能化在这里十年内不管在学术研究還是产业链,的确获得了长足的进步,也逐渐融进我们的日常生活。IEEE Spectrum在2018新春发布专刊"AI vs. Doctors",统计分析了从二零一六年五月迄今,人工智能化与人们医师的交锋。在其中,肺部感染,心脏疾病和脑中风等病症的确诊精确度,人工智能化远超人们医师的水准。
先来简易介绍一下如今的人工智能化在影像医学行业是怎样工作中的。例如要让电子计算机来依据一幅患者的CT照片,分辨这个人是不是得了癌病。总体目标比较简单,是个二分类难题,就跟我说得没有癌病,要让这个问题利用计算机获得处理,必须历经三个流程。提前准备很多患者的CT数据。在其中既包含身心健康的,又包含得癌病的,而且每一幅CT都必须标识好这一患者得没有癌病,称之为标识。依据照片和标识,训炼电子计算机。用的方式便是让电子计算机的分辨越贴近标识越好。代价函数(objective function)在这其中具有了关键的功效,代价函数便是当估计值与具体值不符时给学生的处罚。设想你需要让一个小孩子学习培训什么叫iPhone,就给他们看一张苹果的照片人工投票刷票多少钱,他说道是梨,你给一个巴掌,是水蜜桃,给一个巴掌,是大樱桃,给一个巴掌,直至他说道是iPhone,陪一个笑容 。下一次再给此外一张苹果的照片,他很有可能还会继续犯错误,可是渐渐地的,为了更好地让成本处罚愈来愈小,小孩子就懂了什么叫iPhone。大家便是根据界定那样的代价函数来训炼电子计算机的,让这一成本也就是说是出现偏差的原因在学习培训的全过程微变的愈来愈小。检测这一电子计算机分辨癌病的准确率有多大。这一环节必须提前准备新的患者的CT数据,自然也是标识好的。说白了的举一反三,如同期末考一样,教师通常不容易出平常授课一模一样的题型,来分辨学员究竟把握了沒有。
汇总一下,三步十分的清楚:提前准备数据信息,训炼电子计算机,检测电子计算机。这就是现阶段流行的人工智能化运用在具体难题中的流程,针对客户而言,就仅仅应用训炼完的“智能服务”就可以,例如如今挺火的指纹验证,面部识别,无人驾驶这些,身后全是先历经了那样的三个流程才能够出示服务项目的。
大家把上边的学习方法称之为无监督学习(supervised learning),也叫监管训炼或是有教师学习,电子计算机根据早已出示的标识来学习培训。无监督学习的定义很早以前的情况下就普遍出現在了深度学习的行业,可是绝大多数科学研究都卡在了第二步和第三步,由于流程2训炼的实体模型不足好,造成 流程3的检测精确度不尽人意,因此 学者又返回流程2,就是这样一直循环系统下来。因为近些年的神经元网络优化算法和并行处理的改进,训炼的电子计算机比过去大幅的提高了,在许多 行业乃至检测的情况下精确度能超出人们权威专家的水准。这就是为何近十年那样的监管培训模式会那么的受欢迎,大家称作“深度神经网络”(deep learning)。
殊不知,深度神经网络能充分发挥那样的精密度是有十分关键的前提条件的,那便是必须大量的流程1中的标识数据信息,这也是它的死穴。我给一个大约的叙述,在人工智能算法行业,什么叫做“标识图象”,什么叫做“必须许多 ”。现阶段较大 的标识数据ImageNet有1400多万元幅照片,包含2万好几个类型。Microsoft COCO是物件切分的数据,一共有超出32万幅图,里边的全部物件都人为因素地切分开过。这类总数和品质的标识数据信息,在医药学图象,或是别的行业是难以做到的。而深层学习方法由于其多元性,当标识数据信息不足时经常没有办法媲美一般的传统式方式(图1),也就是难以做到人们的精确度,标识数据信息变成了深度神经网络运用落地式的一个关键短板。如何解决这个问题呢?


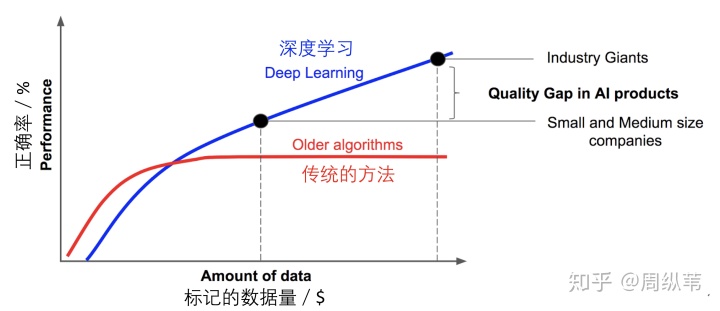 图1 深度神经网络 vs. 传统式优化算法
图1 深度神经网络 vs. 传统式优化算法
2个方位:一、瘋狂的请人标识二、探寻新的学习方法。2. 处于被动学习培训与独立思考
先而言第一个构思,请人标识。这一方式尤其看领导者的水准,一些企业便是确实干掏钱请人标识,尤其的低效能而且烧钱,做的较为聪慧的企业是根据自身的商品潜在性地打标识,举个例子Facebook集团旗下的Instagram,这是一个相近新浪微博的商品,客户在发布自身的相片的另外能够挑选有关的标识(Tag),也等同于新浪微博中的#话题讨论#。那样Facebook每日都是有很多的标签数据涌进,她们必须做的仅仅维护保养好这一绿色生态,涌进的标签数据立刻有用于训炼她们的“人工智能化”,相反让Instagram更“懂”客户,全部商品绿色生态获得一个良好意见反馈。自然这一标识数据现阶段都还没公布,她们在上面早已刚开始做一系列的科学研究了(Exploring the Limits of Weakly Supervised Pretraining)。也有为了更好地搜集无人驾驶轿车的标识数据信息,行车导航,语音通话这些,相匹配的企业都能够十分轻轻松松的设计方案一系列的方式完成源源不绝的获得潜在性的标识。此外我发现了十分聪慧的标识方式是根据一些短信验证码。还记得在登陆一些网址的情况下会出現人工投票刷票多少钱,请挑出来包括“猫”的照片,那样的认证,实际上身后是一整套的投票标识对策,她们并不一定请人去确实标识,由于绝大多数人的回答都应该是恰当的,也就是说,绝大多数的回答应该是一致的,这些和绝大多数人不一致的回答便是有误,这一假定完成的前提条件是检测的样版充足多。因此 这些认证图会数次的被不一样的人标识,最后投一个票就能获得一个精密度很非常好的数据了。这儿隐隐约约采用了“互联网大数据”和“大数定理”的统计分析定义。近期微信朋友圈挺火的游戏,在其中非常大一部分也是为了更好地搜集数据信息的标识,聪慧的领导者把这个让客户标识全过程包裝成好玩的小游戏,或是抽奖活动,或是一些很细微的奖赏,身后得到 很多的标识数据信息。再举一个事例,有一种手机app(照相不容易摆POSE?Posing App软件来帮你),它专业承担具体指导客户摆pose,它会在照相机显示屏上得出强烈推荐的一系列pose的框图,随后客户就依照手稿摆pose就可以。这一身后能够爬取很多的有效标识是么?例如哪里是脸,哪里是手臂。像那样用十分聪慧的方式来搜集数据信息和标识,在我这里是较为看中的“互联网大数据”时期的对策,而且大有文章可做。



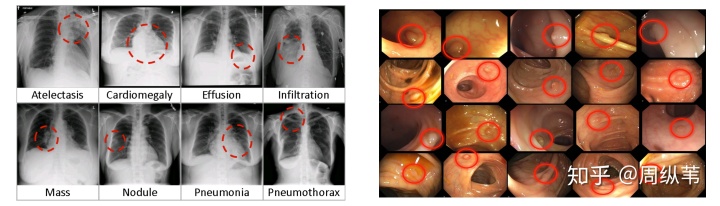 图2 影像医学并不是一般人能标底
图2 影像医学并不是一般人能标底
返回影像医学上,不久说的这些直接了当的方式很有可能在医药学行业难以完成,关键缘故是这不是平常人能进行的每日任务,因此 并不是产品设计反馈调节的事情。在影像医学的标识难题中,仅有贵和更贵2个,较为幸运的是一些病症权威专家是可以用人眼见到而且得出恰当分辨的,例如肠胃的初期恶性肿瘤囊肿检验(图2),可是大量的状况,是必须根据活物检测的,并不是靠人的眼睛就能进行的每日任务,这类标识,像我一开始的事例,分辨得没有癌病,通常是穿刺活检的精标识,搜集这类数据确实能贵死。大家的终极目标是超出人们权威专家,因此 在训炼电子计算机的情况下就不能用人们权威专家的标识,假定权威专家的精确度是60%人工投票刷票多少钱,那麼不管你训炼一个多好的实体模型,最终撑死了也是60%,因而,必须很多活物检测的精标识。
更清楚地界定一下难题自身:1. 手头上有很多沒有标识信息内容的照片2. 因为人力资源和资金的限定,只有获得在其中一部分的标识
在这类具体情况的设置下,大家怎样更合理地运用“人工智能化”?
我详细介绍深度学习中,一样也是在人们学习中的2个学习方法:处于被动学习培训(negative learning)与独立思考(active learning)。学习培训有处于被动和积极之分,也就是说白了“要我教”和“我要学”之别。大家称传统定义上的深度学习,也就是先掏钱把现有的数据信息所有标好,随后一股脑儿败给电子计算机,让它从这当中学习培训,那样的方式为处于被动学习培训,也就是学习培训的样版并分不清次序,分不清难度系数,分不清依次地传递。自然也是有相对性应的独立思考,即先花一部分的钱来训炼电子计算机,随后依据电子计算机的意见反馈,有目的性地去把钱用在标识更关键的样版上,进而让学生在短期内,短投入的状况下尽可能地学得更多种多样,更合理地信息内容。这就是我们在17年的CVPR中发布的工作中(Fine-Tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally)要想传送的信息。独立思考的关键难题是:#p#分页标题#e#怎样界定对当今学生而言更关键的样版?
大家发觉,现如今深度神经网络下的无监督学习真实的门坎变成了非常简单定义——钱。这一钱有两个很重要的流入,一是电子计算机的计算工作能力(GPU Power),二是标识数据信息的总数。这里就引出来一个很重要的难题:`是否训炼数据越多,电子计算机的实际效果会越好呢?`回应这个问题必须展现的結果非常简单,横坐标轴是标识的样本数,纵坐标是归类的精确度。一般来讲,人的思维定势会推动一个默认设置的构思,便是训练样本愈多愈好,如